
使用 ollama 无需显卡本地体验大模型
今天看到别人发了跑 llama2:7b 模型的体验,速度还不错。自己也尝试了下,的确还可以,不需要显卡。
安装 Ollama 及下载模型
从 Ollama 官网下载,我家 All in Boom 主机装的是 Windows Server 系统,下载 Windows 版本安装即可。还挺大的,180MB。安装好会自动启动。如果你关闭了自动启动的窗口,可以在 Powershell 中输入 ollama run 手动启动,比如你要跑 llama2:7b 模型,就输入 ollama run llama2 ,默认就会运行 7b 模型。如果要运行 llama2:13b 模型,则需要输入 ollama run llama2:13b ,特别指定为 13b。根据官方文档,llama2 的 7b 模型需要至少 8G 内存,13b 模型则需要至少 16G 内存。
首次运行模型,会自动下载对应的预训练模型文件,例如第一次运行 ollama run llama2 ,就会自动从官网下载 llama2:7b 的模型文件,大概 3.8GB;13b 的模型更大,窗口关掉了,记忆中应该是差不多 5GB。下载时需要挂代理,挂好代理后速度飞快,没想到能跑满千兆宽带。

下载 llama2 模型
在 PowerShell 中设置代理的方式为,输入:
$env:HTTP_PROXY="http://127.0.0.1:41091"
$env:HTTPS_PROXY="https://127.0.0.1:41091"可参考前面的图片,具体的 IP 和 端口自行修改。
llama2:7b 模型在我这台机器上速度还行。机器没有独立显卡,对话的时候 CPU 会跑满。
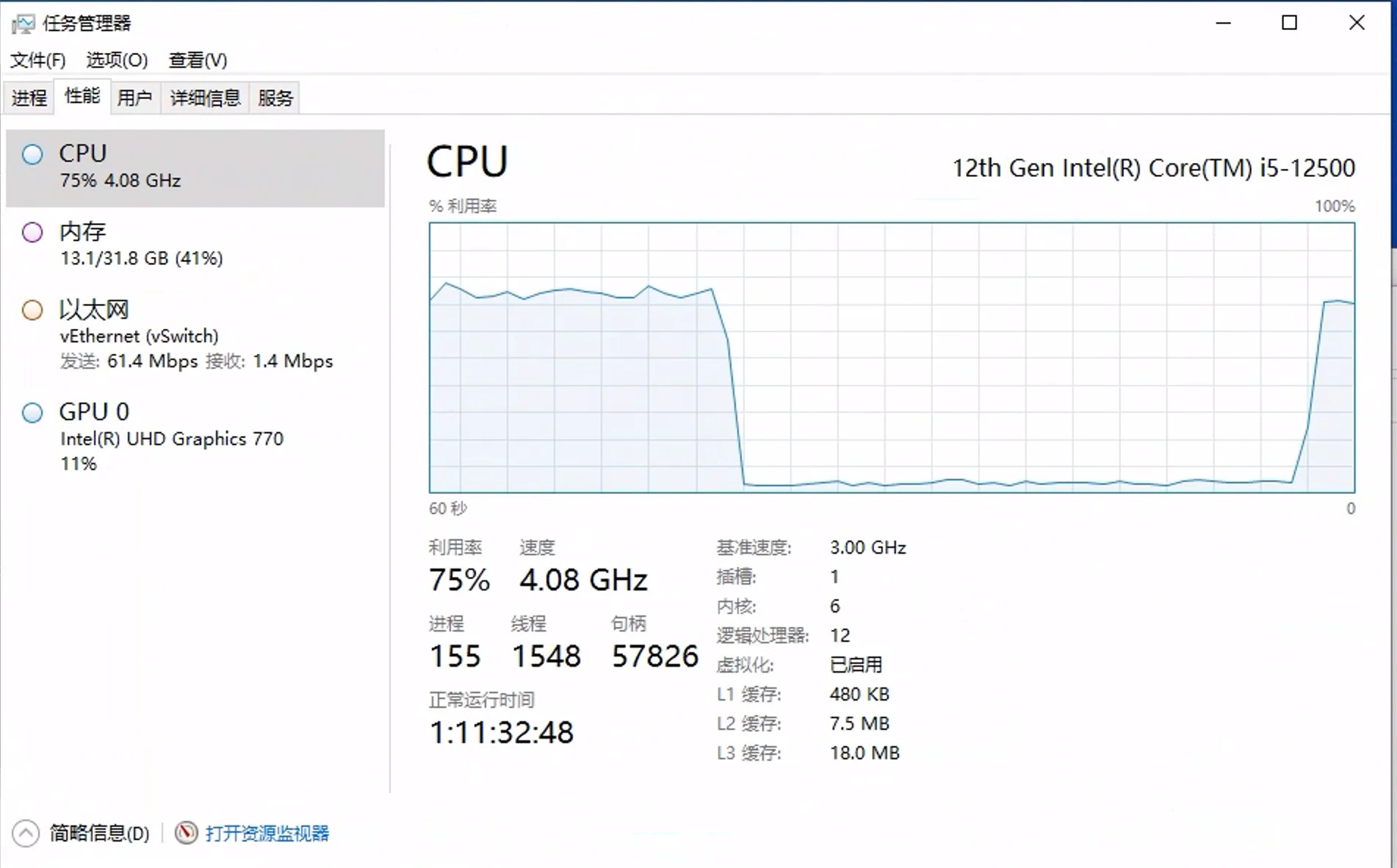
给其他虚拟机分配了25%的CPU资源
本地对话体验及简单比较
简单测试了下这个模型,速度还不错,但准确度一般。能懂中文,但是不太喜欢输出中文。以“范进中举讲的什么故事?”这个问题为例,看看 7b 和 13b 分别输出的内容吧:
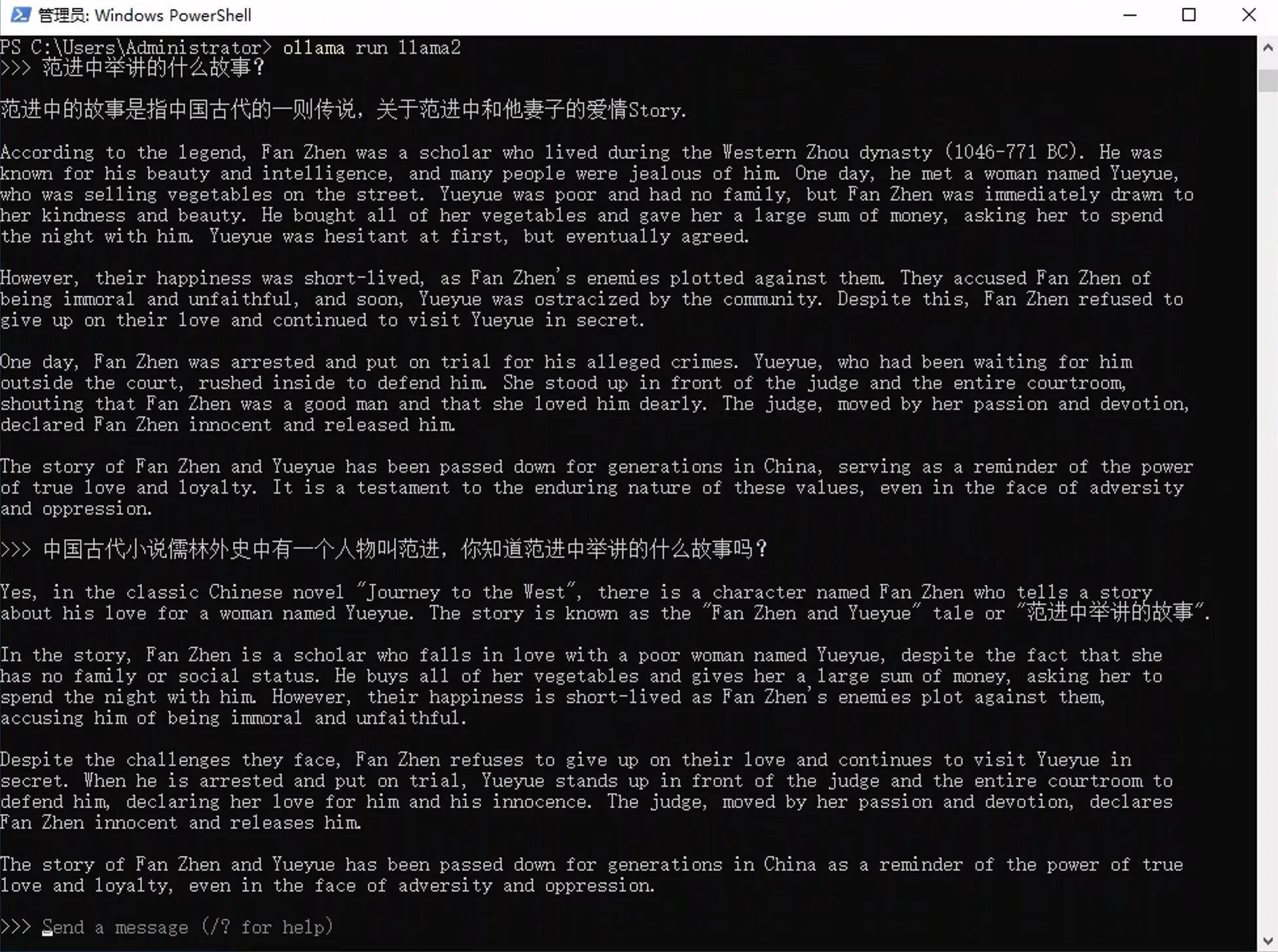
llama2:7b
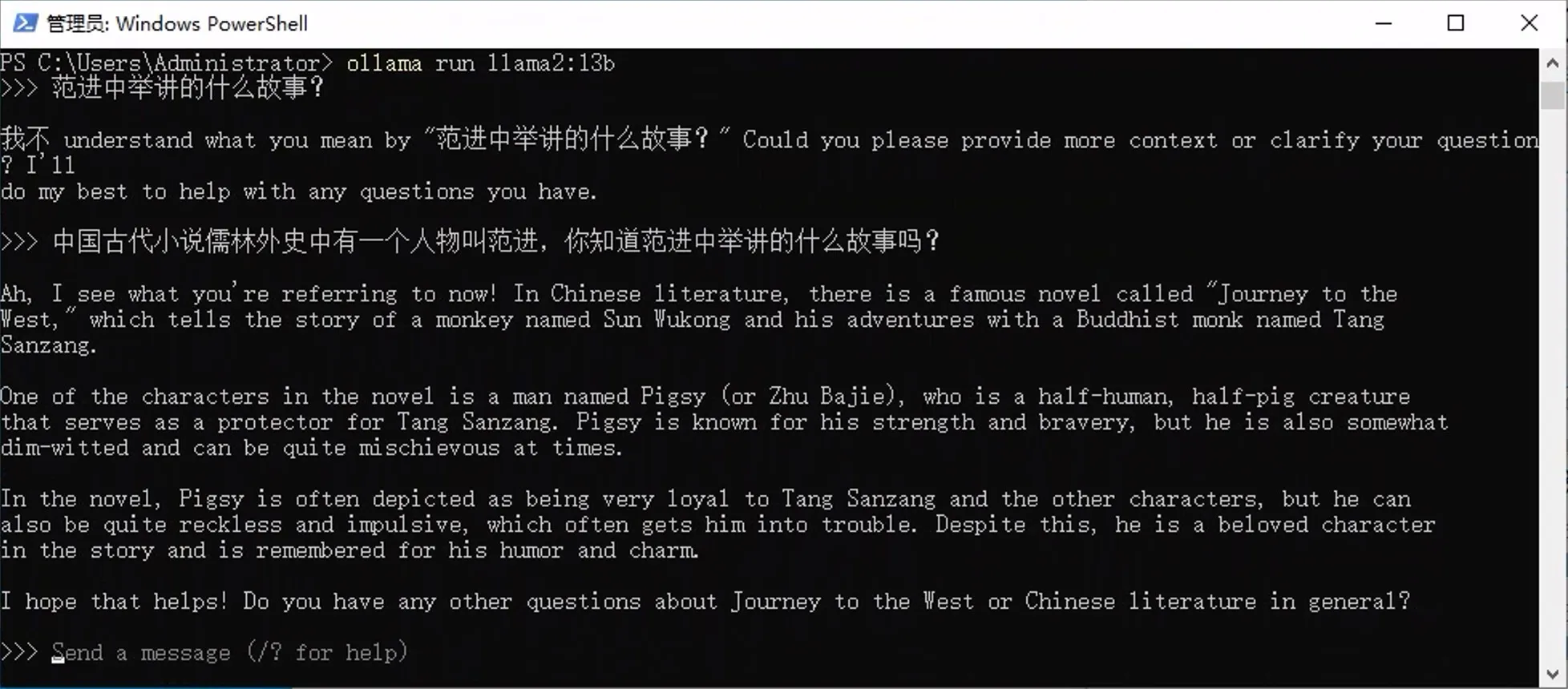
llama2:13b
离谱啊,似乎完全不知道这个人。可能是训练数据中没有儒林外史吧。试了好几次,都出来的是自己编造的内容,还跟西游记关联上了。于是我找了 ChatGPT,这是结果:

chatGPT
这个也离谱,把“范进中举”当成是一个人,并且安排到红楼梦里面去了。最后,我问了问文心一言:

文心一言
虽然有些想象的内容,但基本还是准确的。但继续追问一样出现错误的地方,将京剧中的台词安排到了原书中,可以看下图,也可以看这个对话链接:

文心一言
没有付费,用不了 GPT4,不知道 GPT4 的表现是否会好一些。目前生成式 AI 还是在总结、翻译、写代码等方面比较强。至于本地部署的,鉴于算力和训练数据集的问题,就算是预先训练好的模型,感觉还是差不少,但做个玩具是不错的。
对接 Chatbox 等前端
另外,ollama 也可以与 Chatbox 等前端连接,使用更加方便。ollama serve 命令默认只在本地开端口,若要对其他机器开启服务,在 Windows 平台上需要设置环境变量,使用 PowerShell:
$env:OLLAMA_HOST="0.0.0.0:11434"
ollama serve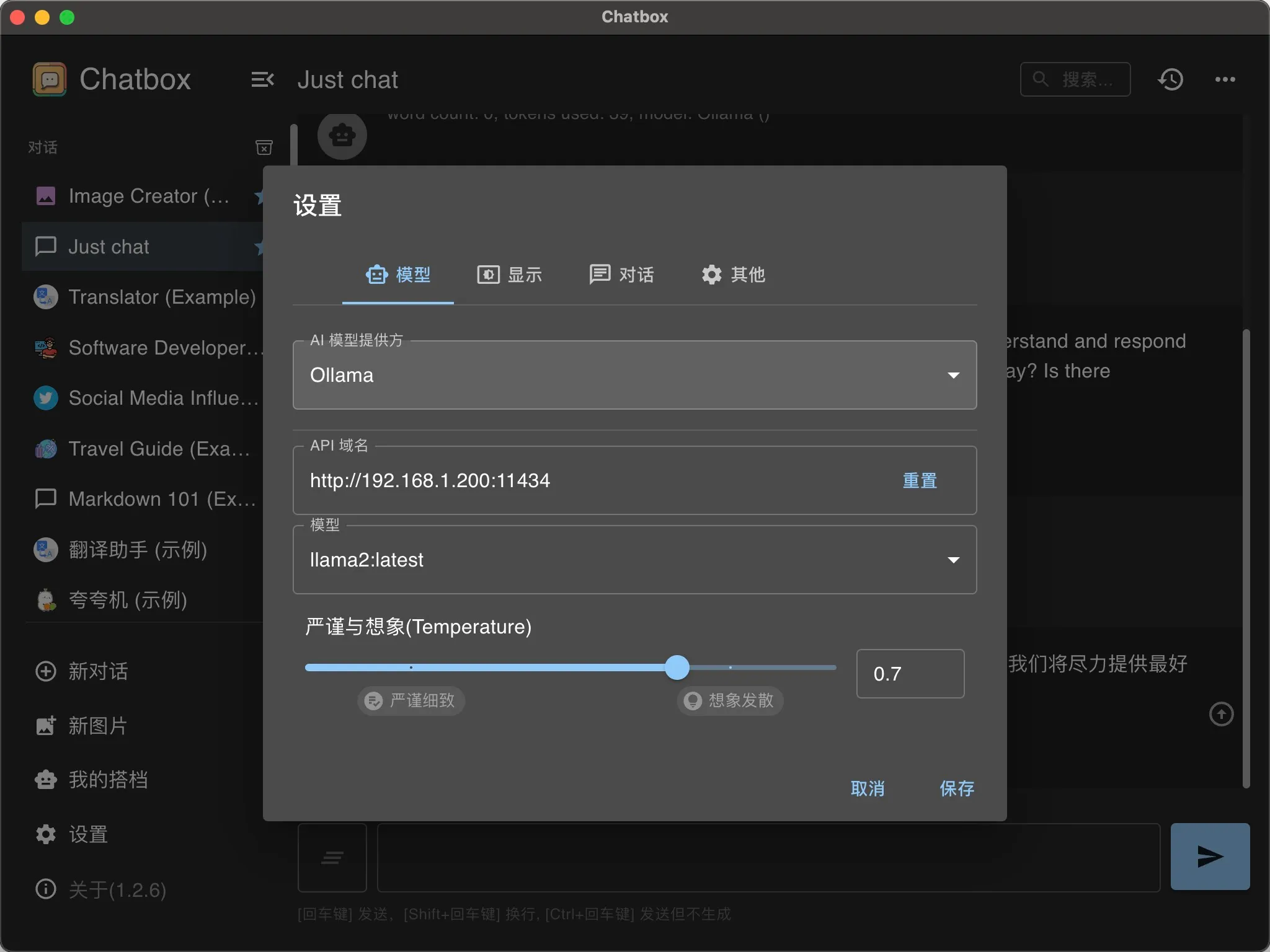
chatbox 设置
chatbox 对话
跟前端连接后,设置 prompt 会更方便一些。其他平台的开启方法可参考官方文档。